























Im letzten Teil der Serie analysieren wir eine weitere Binärdatei mit Ghidra. Dieses Mal nutzen wir einen anderen Analyse-Ansatz, mit dem wir auch in größeren Programmen schnell wichtige Stellen ermitteln können, die uns Auskunft über die Funktionsweise des Programms geben. Außerdem finden wir obfuskierte Daten, die wir in eine verständliche Form bringen.
Wir starten mit dem folgenden Quellcode:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
#include <netinet/in.h>
#include <arpa/inet.h>
char reqType [] = { 0x75,0x76,0x60,0x12,0x1c,0x14,0x7a,0x67,0x60,0x62,0x1c,0x05,0x1c,0x02,0x39,0x38,0x33 };
char host [] = { 0x7a,0x5c,0x47,0x46,0x09,0x14,0x55,0x57,0x55,0x46,0x52,0x1a,0x56,0x56,0x39,0x38,0x33 };
char end [] = { 0x3f,0x39,0x34 };
char hostname [] = { 0x55,0x57,0x55,0x46,0x52,0x1a,0x56,0x56,0x34 };
int addEight(int a){
for (int i=0; i<8; i++)
a = a+1;
return a;
}
int quadrupleNumber(int a){
int b = a;
for (int i=0; i<4; i++)
a = a+b;
return a;
}
char* xorData(char* data, int size){
char xorKey [] = { 0x32, 0x33, 0x34 };
for (int i = 0; i<size; i++)
data[i] = data[i] ^ xorKey[i % 3];
return data;
}
char* getRequestHeader(){
xorData(reqType, sizeof(reqType));
xorData(host, sizeof(host));
xorData(end, sizeof(end));
char header[36];
strcpy(header, reqType);
strcat(header, host);
strcat(header, end);
return header;
}
void sendRequest(char* header){
struct sockaddr_in serv_addr;
struct hostent *he;
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
xorData(hostname, sizeof(hostname));
he = gethostbyname(hostname);
bzero((char *)&serv_addr, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(80);
serv_addr.sin_addr = *((struct in_addr *)he->h_addr);
connect(sockfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
send(sockfd, header, sizeof header, 0);
}
int main(int argc, char *argv[]){
int a = 15;
int b = 17;
a = a+b;
b = quadrupleNumber(b);
a = addEight(a);
a = a+b;
char* header = getRequestHeader();
a = addEight(a);
a = quadrupleNumber(a);
a = addEight(a);
b = addEight(b);
sendRequest(header);
a = addEight(a);
a = quadrupleNumber(a);
return 0;
}In unserem Beispiel befindet sich der Code in der Datei RequestProgram.c. Diese kompilieren wir erneut auf einem Linux-System für die x86-Architektur.
gcc RequestProgram.c -o RequestProgram -s -m32Wie im vorherigen Artikel importieren wir das Programm und lassen Ghidra eine automatische Analyse durchführen. Anschließend suchen wir die entry-Funktion und sehen, dass dort die Funktion FUN_0001141d gestartet wird. Wir benennen diese in main um und sehen uns den dekompilierten Code an.
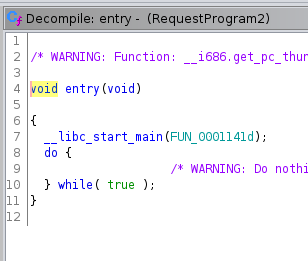
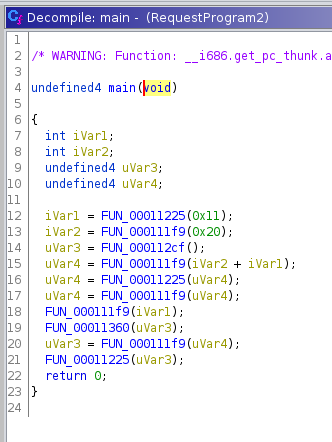
Im Vergleich zum vorherigen Beispiel sind diesmal deutlich mehr Funktionsaufrufe vorhanden. Die Anzahl hält sich zwar immer noch in Grenzen, sodass wir uns jede einzelne Funktion ansehen könnten, wir wählen diesmal mit dem Bottom-Up-Ansatz aber eine andere Herangehensweise.
Bottom-Up-Ansatz
Beim Bottom-Up-Ansatz suchen wir „interessante“ Stellen und arbeiten uns von dort nach oben, um zu prüfen, ob diese Stellen auch tatsächlich aufgerufen werden.
Zur Identifikation der „interessanten“ Stellen nutzen wir die aufgerufenen Funktionen und Zeichenketten, die Ghidra identifiziert hat. Über den Menüpunkt Window -> Defined Strings bzw. Functions lassen sich entsprechende Fenster anzeigen. In der Liste der Zeichenketten finden sich Einträge wie socket, connect, gethostbyname, etc., die darauf hindeuten, dass das Programm Netzwerkverkehr durchführt. Durch eine Internetsuche – insbesondere mit dem Suchtext gethostbyname – stellt man fest, dass es sich um Namen von C-Bibliotheksfunktionen handelt. Daher sind entsprechende Einträge auch in der Liste der aufgerufenen Funktionen zu sehen.
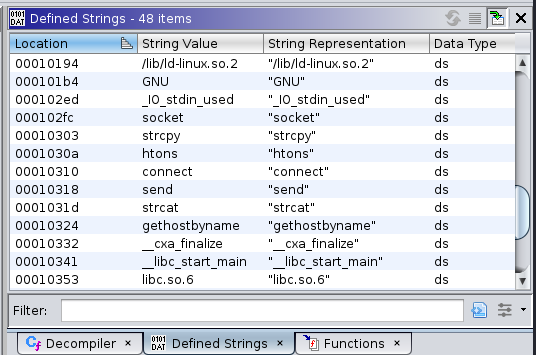
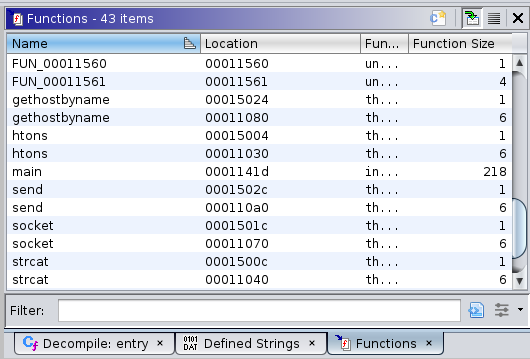
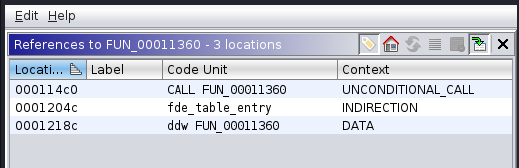
Die Funktion gethostbyname ist insbesondere deshalb interessant, weil dort als Funktionsargument entweder der Name oder die IP-Adresse des Hosts eingeht, mit dem eine Verbindung hergestellt werden soll. Falls tatsächlich Netzwerkverkehr stattfindet, würden wir dort das Ziel erkennen. Deshalb sehen wir uns an, an welchen Stellen die Funktion aufgerufen wird. Dazu wählen wir den Eintrag an der Adresse 0x0011080, wodurch die Ansicht der Disassembly an die entsprechende Stelle springt. In grüner Schrift sehen wir dort eine Referenz (XREF), über die wir in die Funktion springen, in der gethostbyname verwendet wird. Alternativ können wir uns auch über das Kontextmenü oder die Tastenkombination Strg+Shift+F die Referenzen anzeigen lassen.
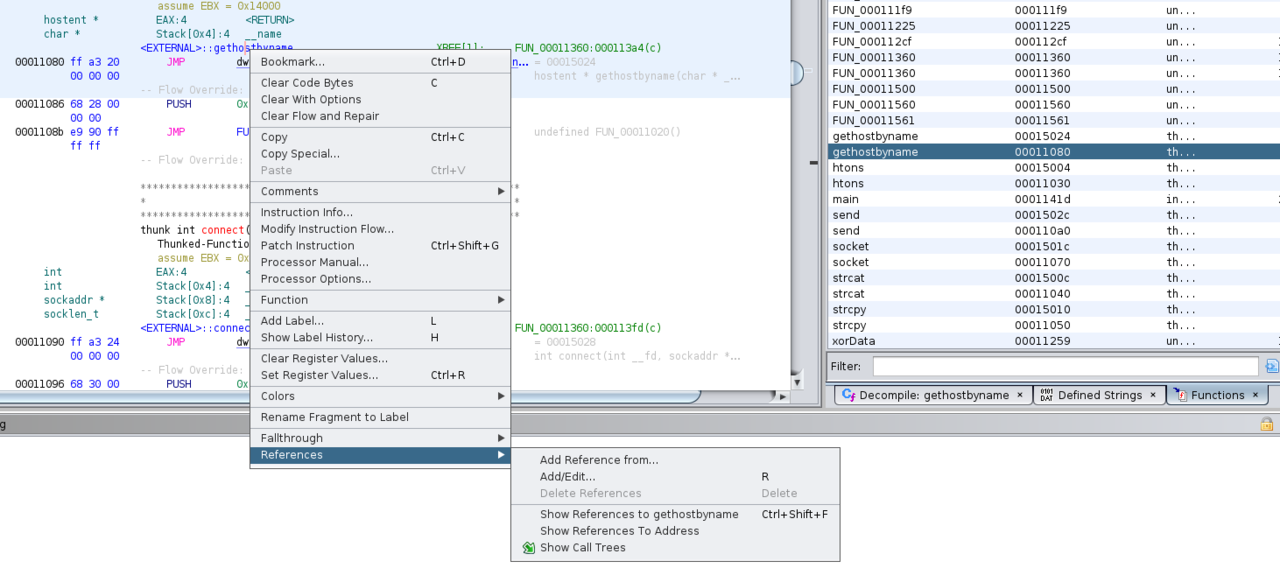
In der Funktion FUN_00011360 sehen wir den Aufruf von gethostbyname. Später folgen außerdem die Funktionen connect und send. Falls die Funktion FUN_00011360 verwendet wird, findet demnach Netzwerkverkehr statt. Wir prüfen die Referenzen der Funktion und stellen fest, dass sie in der main-Funktion aufgerufen wird und daher tatsächlich relevant für unsere Analyse ist.
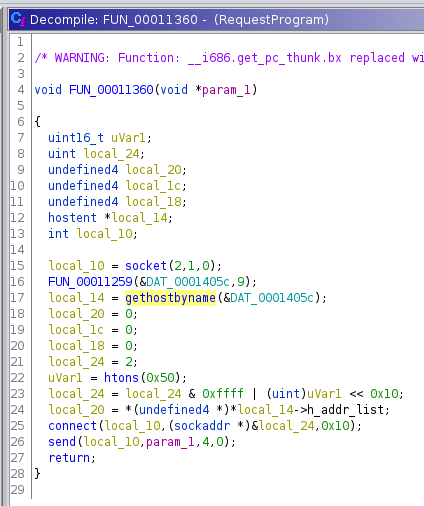
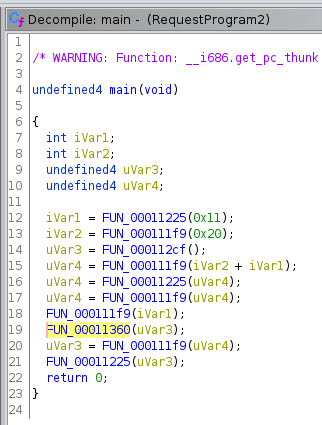
Als nächstes wollen wir wissen zu welchem Host eine Verbindung aufgebaut wird. Dazu werfen wir erneut einen Blick auf den Aufruf von gethostbyname. Wie oben erwähnt, erhält die Funktion als Argument entweder den Namen oder die IP-Adresse des zu kontaktierenden Servers, bzw. genauer gesagt einen Pointer, der auf den entsprechenden Datenbereich zeigt. Schauen wir in den verwendeten Datenbereich DAT_0001405c, erkennen wir dort aber weder das eine noch das andere. Stattdessen sehen wir neun Bytes, die auf den ersten Blick keinen Sinn ergeben. Die Daten sind obfuskiert.
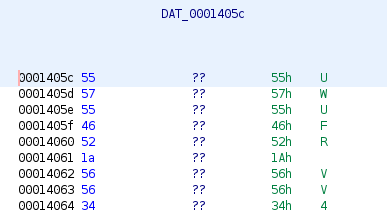
Bei der Ausführung des Programms müssen die Daten irgendwann deobfuskiert werden, damit Informationen für den richtigen Host ermittelt werden. Es muss demnach eine Funktion geben, in der der Datenbereich verändert wird.
Ein erster Anhaltspunkt ist die Funktion FUN_00011259, die direkt vor dem Aufruf von gethostbyname verwendet wird und den obfuskierten Datenbereich als Argument erhält. Außerdem wird die Zahl 9 übergeben, was der Länge des Datenbereichs entspricht. Wir untersuchen die Funktion deshalb genauer.
Ohne Anpassungen ist die Funktion zunächst etwas unübersichtlich. Um Ordnung und eine bessere Übersicht zu schaffen, nennen wir zuerst die beiden Funktionsparameter param1 und param2 in data und length um. Außerdem ändern wir den Datentyp von data in einen Byte-Pointer. Durch diese Anpassungen können wir bereits gut erkennen, dass jedes Byte des Datenbereichs durchlaufen wird und der XOR-Operator angewendet wird.
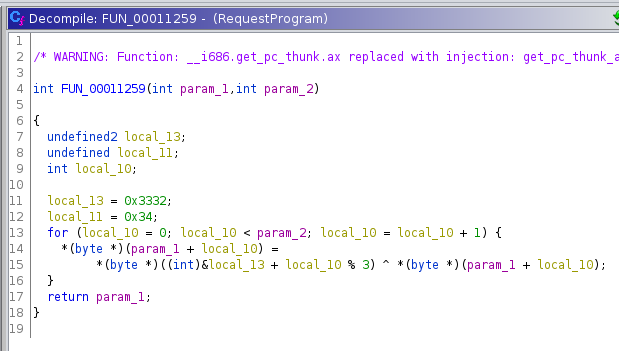
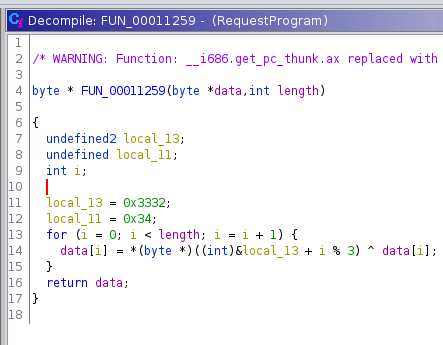
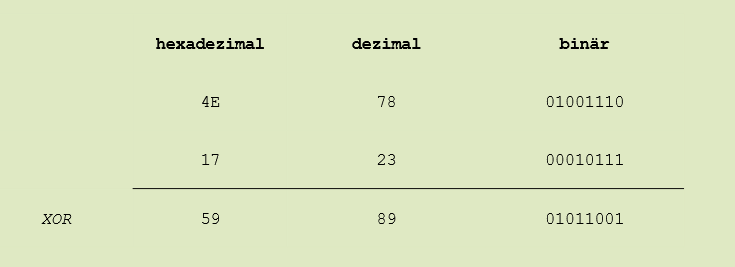
Bei der XOR-Operation findet ein Vergleich der einzelnen Bits der Operanden statt. Nur wenn genau eins der beiden Bits auf 1 gesetzt ist, ist das Bit an der Stelle im Ergebnis ebenfalls 1.
Beispiel: 4E ^ 17
Nun müssen wir nur noch ermitteln mit welchem anderen Operanden das XOR ausgeführt wird. Auch hier verhilft die richtige Typisierung zu einer besseren Übersicht. Wir sehen, dass die Variable local_13 Teil der XOR-Operation ist und Typumwandlungen (Casts) durchgeführt werden. Die Kombination von Casts auf Pointer und Integer deutet dabei daraufhin, dass es sich lediglich um einfache Pointer-Arithmetik handelt, wie sie beispielsweise bei Zugriffen auf Arrays vorkommt.
Wir erkennen außerdem, dass der Variablen local_13 die Bytes 0x32 und 0x33 zugewiesen werden und in der nächsten Zeile die Variable local_11 als Wert 0x34 erhält. Ghidra hat hier keinen Zusammenhang erkannt und daher einzelne Variablen ermittelt. Mit der Überlegung, dass es sich um ein Array handelt, setzen wir den Datentypen der Variable local_13 auf ein Byte-Array der Länge 3, wodurch die Variable local_11 verschwindet.
Nun ist deutlich erkennbar, dass die Funktion genutzt wird, um den XOR-Operator auf den übergebenen Datenbereich und das Bytearray { 0x32, 0x33, 0x34 } anzuwenden.
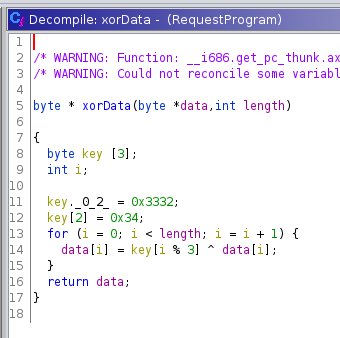
Wenn wir die Größe des Arrays nicht direkt auf 3 gesetzt hätten, wäre bei der Prüfung des Codes aufgefallen, dass in der Schleife eine Modulo-Operation mit 3 stattfindet. Aus dem Array werden folglich die Werte an der Stelle 0, 1 und 2 verwendet, sodass es sinnvollerweise eine Länge von 3 haben muss.
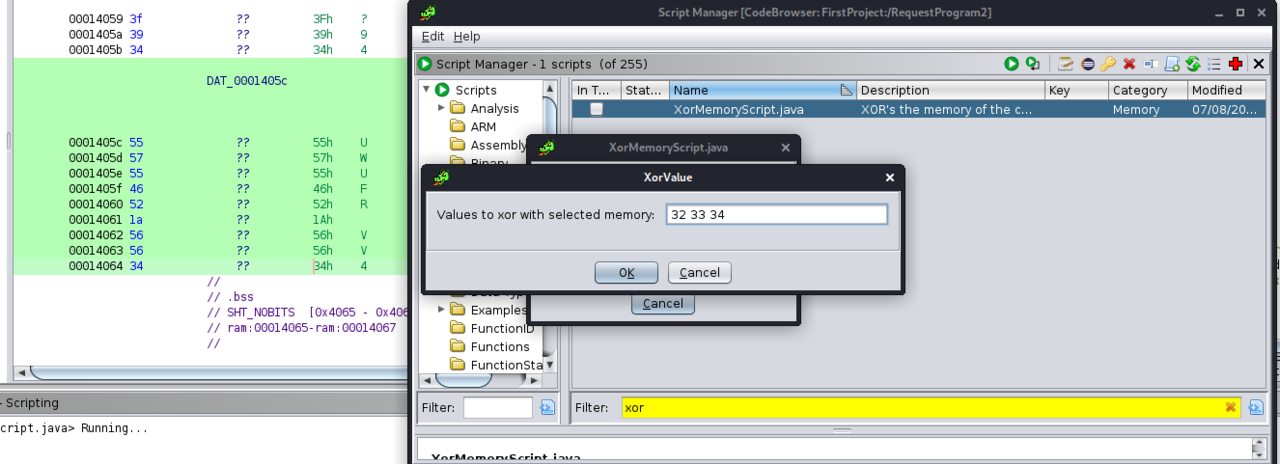
Mit diesen Informationen können wir den Datenbereich deobfuskieren und ermitteln welcher Host kontaktiert werden soll. Ghidra stellt praktischerweise ein Skript zur Verfügung, mit dem die XOR-Operation auf Speicherbereiche ausgeführt werden kann.
Dazu springen wir erneut zum Speicherbereich DAT_0001405c und markieren die Daten. Anschließend wählen wir im Script Manager (Window -> Script Manager) das XorMemoryScript aus und führen es aus. Es erscheint ein Pop-Up, in dem wir die Werte 32 33 34 eingeben und mit OK bestätigen. Die Werte im Datenbereich haben sich verändert. Setzen wir den Datentyp per Rechtsklick -> Data -> string auf eine Zeichenkette sieht man, dass das Programm gdata.de als Hostnamen verwendet.

Bei einer tiefergehenden Analyse würden wir das Programm noch weiter untersuchen und beispielsweise herausfinden welche Daten gesendet werden. (Spoiler: Das Programm sendet einen einfachen GET-Request. Die Daten sind ebenfalls per XOR obfuskiert). Wir beenden an dieser Stelle aber unser Beispiel.
Die Obfuskierung über die XOR-Operation ist leicht zu erkennen und rückgängig zu machen. Bereits eine solch einfache Methode kostet die Analyst*innen mehr Zeit als die Analyse eines Programms, das auf Obfuskierung verzichtet. Es ist leicht vorstellbar, dass es andere Varianten gibt, die die Analyse noch weiter erschweren. Mitunter existieren in einer Datei auch mehrere Schichten an Obfuskierung, oder die Autor*in hat bestimmte Teile vorher noch verschlüsselt. So weiß jemand, der die Datei analysieren will, manchmal nicht sofort, ob mit dem entschlüsselten Inhalt etwas nicht stimmt oder dieser noch zusätzlich obfuskiert ist. Tatsache ist jedenfalls, dass eine gut gemachte Obfuskierung das Reverse Engineering massiv erschweren kann. Eine eingehende Analyse kann sich so über Stunden oder Tage hinziehen.
Auch wenn Obfuskierung oft in Schadsoftware eingesetzt wird, ist deren Vorhandensein jedoch nicht zwangsweise ein Indikator dafür, dass eine Datei definitiv schädlich ist. Sie kann ebenfalls Teil einer Strategie sein, um den Diebstahl geistigen Eigentums (etwa in kommerzieller Software) zu verhindern.
Diese Artikelreihe kann natürlich nur ein Schlaglicht auf dieses komplexe Themenfeld werfen und dieses auch nicht in Gänze erfassen. Das würde den Rahmen eines Blogs sprengen. Ich hoffe jedoch, Interessierten einen kleinen Einblick in die Materie gegeben zu haben - und vielleicht möchten einige Menschen nach der Lektüre dieser Reihe mehr wissen. Für Menschen, die schon Erfahrungen im Reverse Engineering und Malware-Analyse haben, lohnt sich auch ein Blick auf unsere Karriere-Seite.


