























Reverse Engineering ist der Versuch, aus einem fertigen Objekt den zugrunde liegenden Bauplan zu rekonstruieren. Im Falle des Software Reverse Engineerings geht es dabei meist darum aus einem ausführbaren Programm den ursprünglichen Quellcode wiederherzustellen. Dadurch lässt sich z. B. besser analysieren, ob es sich bei einer Datei um eine Schadsoftware handelt. In einer mehrteiligen Serie geben wir einen grundlegenden Einblick in das Reverse Engineering. Dabei behandeln wir sowohl theoretische Grundlagen, als auch die praktische Anwendung von entsprechenden Tools.
Im ersten Teil stellen wir vor, was beim Reverse Engineering überhaupt geschehen muss. Der Fokus liegt dabei auf nativen Binärdateien d.h. Dateien, die speziell für ein Betriebssystem und eine Prozessorarchitektur generiert werden. Dazu zunächst eine Übersicht wie eine solche Binärdatei erzeugt wird.
Hochsprache zu Maschinencode
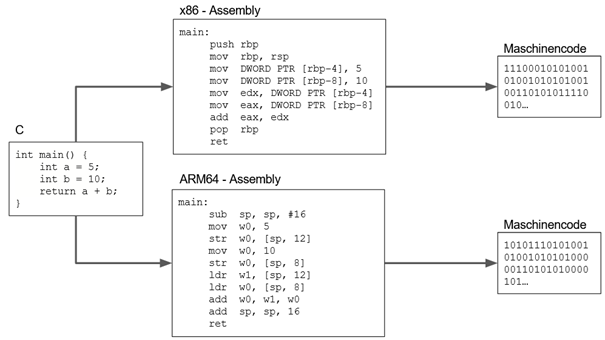
Jede Person, die etwas programmiert hat, hat schon einmal Quellcode in einer der vielen Programmiersprachen gesehen. Hier ein einfaches Codebeispiel in der Programmiersprache C:
int main() {
int a = 5;
int b = 10;
return a+b;
} Code in einer solchen Hochsprache ist für uns Menschen mit ein wenig Übung gut lesbar und verständlich. Doch ein Computer kann damit nicht wirklich etwas anfangen. Der Programmcode muss übersetzt werden. Diesen Zweck erfüllen Compiler, die den Code in Maschinensprache - d.h. Einsen und Nullen – und damit in native Binärdateien umwandeln.
Während der Code in Hochsprache fast immer unabhängig von der Hardware ist, auf der er ausgeführt werden soll, ist beim Maschinencode das Gegenteil der Fall. Maschinencode hängt von der Architektur des Prozessors ab. Ein Programm, das beispielsweise für ein System mit ARM-Prozessor (z.B. die meisten Smartphones) kompiliert wurde, läuft nicht auf einem „Standard“-Heimrechner mit einem x86-Prozessor.
Es existieren auch Compiler, die den Quellcode in Zwischensprachen wie Java Bytecode übersetzen. Die Ausführung der so kompilierten Dateien kann auf unterschiedlichen Systemarchitekturen erfolgen, sofern auf dem entsprechenden System eine passende Laufzeitumgebung (z.B. Java Runtime Environment mit zugehöriger Java Virtual Machine) vorhanden ist.
So ist es möglich, die gleiche Anwendung auf jedem Betriebssystem laufen zu lassen, für die es eine Laufzeitumgebung gibt. Das macht Java zu einer plattformübergreifenden Programmiersprache, bei der nicht für jede Architektur eine eigens kompilierte Anwendung erforderlich ist.
Assemblersprachen – die oft vergessene Zwischenschicht
Hochsprachen, sind stark vom Maschinencode abstrahiert und am menschlichen Verständnis orientiert. Als Zwischenschicht zwischen diesen beiden eher weit entfernten Ebenen gibt es noch die hardwarenahen Assemblersprachen. Für jede Prozessorarchitektur existiert dabei eine eigene. Eine Anwendung direkt in Assembler-Sprache zu programmieren, ermöglicht eine sehr schnelle und performante Umsetzung der jeweiligen Befehle, weil der Zwischenschritt über einen Compiler – der möglicherweise die Hochsprache nicht optimal übersetzt - entfällt. Die Programmbefehle liegen in einem Format vor, das wesentlich hardwarenäher ist. Das geht jedoch zu Lasten der Kompatibilität mit anderen Plattformen. Zudem ist Assembler im Vergleich zu einer der Hochsprachen wie etwa C oder Java nicht einfach zu lernen.
Die Assemblersprachen wurden entwickelt, um nicht mehr in den Zahlencodes der Maschinensprache programmieren zu müssen, sondern eine für den Menschen leichter verständliche Sprache zu nutzen. So gibt es in Assemblersprachen beispielsweise eine kurze textuelle Darstellung der durchzuführenden Operationen, wie z.B. „mov“ um einen Wert zu bewegen (englisch: move). Dies ist deutlich einfacher zu verstehen als die binäre Repräsentation in Maschinensprache (z.B. 10110000) bzw. die hexadezimale Darstellung (z.B. 0xb0).
In zweiten Teil der Serie werden wir uns die Grundlagen der Assemblersprachen genauer ansehen, daher verzichten wir hier auf eine genauere Erläuterung.
Einige Compiler übersetzen den Hochsprachencode nicht direkt in Maschinencode, sondern in Assemblersprache. Anschließend wird von einem Assembler der finale Übersetzungsschritt durchgeführt.
Es ergibt sich also der folgende Ablauf:
Reverse Engineering
Im Idealfall liegt für eine Analyse eines Programms der Quellcode in einer Hochsprache vor. Damit lässt sich gut nachvollziehen, welche Funktionalitäten das Programm enthält und ob es sich um Schadsoftware handelt. Während das insbesondere bei Malware in Skriptsprachen wie PowerShell der Fall ist, müssen unsere Analyst*innen oft auch kompilierte Dateien evaluieren.
Doch wie funktioniert das, wo Maschinencode – also die Einsen und Nullen - für Menschen unlesbar, bzw. unverständlich ist? Zum Glück gibt es Tools, mithilfe derer Analyst*innen Reverse Engineering durchführen können. Dabei wird z.B. der Maschinencode disassembliert, d.h. in Assemblersprache zurückgewandelt. Einige Analyseprogramme nehmen anhand dieses Ergebnisses auch noch eine Dekompilation vor und versuchen den ursprünglichen Quellcode in einer Hochsprache wiederherzustellen. Das Endresultat ist zwar nicht der originale Code, bietet aber eine ungefähre Vorstellung wie dieser ausgesehen haben könnte - sofern die Autor*innen keine Obfuskierung eingesetzt haben, um das Reverse Engineering zu erschweren. Die Tools versuchen also den oben dargestellten Prozess rückgängig zu machen und die Analyse dadurch zu vereinfachen und zu beschleunigen.
Im nächsten Artikel werfen wir einen Blick auf die Grundlagen der Assemblersprachen, die eine wichtige Basis des Reverse Engineerings bilden.



