























Ghidra ist ein Reverse-Engineering-Tool, das von der US-amerikanischen NSA entwickelt wird und seit 2019 als Open-Source-Software frei erhältlich ist. Es handelt sich dabei um ein Werkzeug, mit dem andere Programme disassembliert und dekompiliert werden können. Seit der Version 10.0 sind zusätzlich auch Funktionalitäten zum Debuggen enthalten.
Installation
Voraussetzung für die Nutzung von Ghidra ist ein 64-bit Betriebssystem und das passende Java 11 Runtime and Development Kit (JDK). Ghidra selbst ist als Zip-Datei hier verfügbar. Da das Tool keinen herkömmlichen Installer verwendet, genügt es, die Datei lediglich zu entpacken.
Falls Sie Kali-Linux nutzen: Ghidra ist seit der Version 2021.2 dort enthalten und wird automatisch mitinstalliert.
Vorbereitung
Auch in diesem Teil gehen wir ein Beispiel Schritt für Schritt durch. Grundlage ist dabei der folgende Quellcode, der sehr ähnlich zu dem aus Teil 2 ist.
#include <stdio.h>
int add_numbers(int a, int b){
int c = 20;
return a+b+c;
}
int main() {
int a = 5;
int b = 10;
int c = add_numbers(a, b);
printf("The result is %i.", c);
return c;
} Der Code befindet sich in der Datei FirstProgram.c, die wir auf einem Linux-System mit der folgenden Befehlszeile für die x86-Architektur kompilieren. (Sie können den Quellcode natürlich auch unter Windows kompilieren. Das Ergebnis wird sich in einigen Stellen unterscheiden, sollte aber ähnlich nachvollziehbar sein.)
gcc FirstProgram.c -o FirstProgram -s -m32Erste Schritte
In Ghidra müssen wir zunächst ein Projekt anlegen. Dies erfolgt über File -> New Project oder die Tastenkombination Strg+N. Hier gibt es die Möglichkeiten ein Projekt lokal auf dem Rechner (Non-Shared) oder ein Projekt auf einem Server anzulegen (Shared), an dem auch andere Personen mitarbeiten können.
Jetzt können wir die kompilierte Datei in das Projekt importieren. Dazu gibt es mehrere Möglichkeiten: entweder über das File-Menü und die Funktion Import File, den Buchstaben i auf Ihrer Tastatur oder durch das Hineinziehen der Datei per Drag&Drop in das Projektfenster. Es öffnet sich ein Pop-Up-Fenster in dem Ghidra anzeigt, welches Dateiformat und welche Sprache es erkannt hat. Mit einem Klick auf OK importiert Ghidra die Datei zeigt noch einmal Informationen zum Import an.
Mit einem Doppelklick auf die gewünschte Datei (oder Drag&Drop auf den Drachen) startet der Code Browser, in dem die Analyse stattfindet. Beim ersten Mal stellt Ghidra fest, dass die Datei noch nicht analysiert wurde und fragt, ob es eine automatische Analyse durchführen soll. Nach der Bestätigung wird ein Pop-Up mit vielen möglichen Analyse-Parametern angezeigt. Für unseren Einstieg beachten wir diese nicht weiter und starten mit einem Klick auf Analyze.
Der Code Browser ist in mehrere Fenster unterteilt, die nach Belieben verschoben und in der Größe verändert werden können. Im Standard befinden sich links Fenster, die Informationen zur Struktur des Programms enthalten. In der Mitte ist ein großer Bereich, in dem das Ergebnis der Disassemblierung zu sehen ist und der rechte Teil enthält ein Fenster, das den dekompilierten Code anzeigt wird. Im unteren Bereich gibt es eine Übersicht über Datentypen und eine Konsole, die Informationen anzeigt, wenn Skripte ausgeführt werden.
Analyse per Top-Down-Ansatz
Wir gehen in diesem Beispiel davon aus, dass wir keinerlei Informationen darüber haben, was das Programm tut. Das ist in der Praxis der Malware-Analyse der Regelfall. In diesem Fall ist der Top-Down-Ansatz eine Möglichkeit, um die Anwendung systematisch zu analysieren. Dabei gehen wir vom Einstiegspunkt der Software aus und arbeiten uns nach unten zu den „interessanteren“ Funktionalitäten.
Im Fenster Symbol Tree unter Exports finden sich mögliche Einstiegspunkte in ein Programm. Bei einer ausführbaren Datei ist dort normalerweise lediglich ein Eintrag mit der Bezeichnung entry zu sehen. Wir wählen diesen Eintrag aus und die Ansichten im Fenster der Disassembly und des dekompilierten Codes springen automatisch an die entsprechende Stelle.
Sehen wir uns den dekompilierten Code der entry-Funktion genauer an. Wir stellen fest, dass dieser nicht in unserem Programmcode enthalten ist. Wie in Teil 2 bereits kurz erwähnt, handelt sich um Code, der für die Ausführung benötigt wird, aber nichts mit der eigentlichen Funktionalität der Software zu tun hat. Dort wird dann die erste Funktion, die aus dem Quellcode stammt - meist die main-Funktion-, aufgerufen. In unserem Beispiel geschieht dies durch den Aufruf der Funktion __libc_start_main, die die Funktion FUN_000111bf startet.
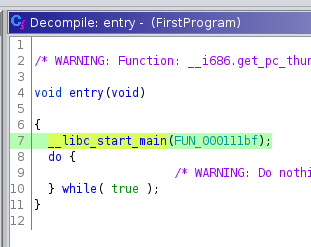
Mit einem Doppelklick auf FUN_000111bf springen wir in die Funktion hinein. Die Funktions- und Variablennamen sind direkt nach der Dekompilierung noch nicht sehr aussagekräftig, da die originalen Namen beim Kompilieren verloren gegangen sind. Außerdem stimmen auch die Variablentypen in vielen Fällen nicht mit den ursprünglichen Typen überein. Hier beginnt die Arbeit der Reverse-Engineers. Um ein besseres Verständnis für den Code zu entwickeln, nehmen wir im Folgenden eine Typisierung vor und geben den jeweiligen Funktionen sinnvollere Namen.
Wir wissen, dass die Funktion FUN_000111bf von __libc_start_main gestartet wird. Daher nennen wir sie in main um. Das erfolgt über Rechtsklick -> Rename Function oder die Taste L. Die Variable uVar1 findet in der printf-Anweisung Verwendung. Da sie dort für den Platzhalter %i eingesetzt wird, wissen wir, dass es sich dabei um einen Integer-Wert handeln muss. Daher setzen wir den Typen der Variablen auf int (Rechtsklick-> Retype Variable oder Strg+L) und nennen sie in result um.
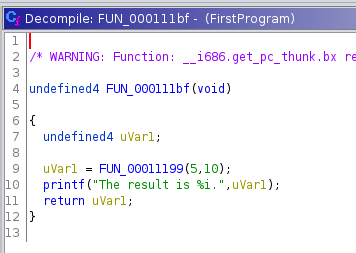
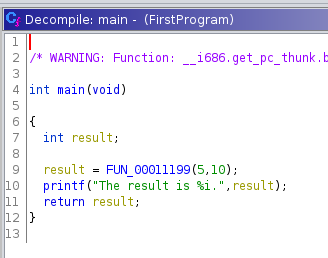
Als nächstes springen wir in die aufgerufene Funktion FUN_00011199. Dort sehen wir, dass die beiden Funktionsparameter und 0x14 addiert werden. Nach einem Rechtsklick auf 0x14 kann die Zahl im Kontextmenü in dezimale Schreibweise konvertiert werden, was an einigen Stellen das Verständnis erhöht. Da außer der Addition nichts weiter passiert, nennen wir die Funktion in add_params_and_20 um.
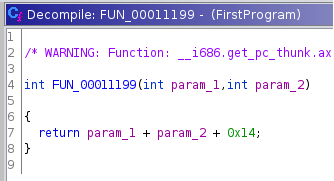
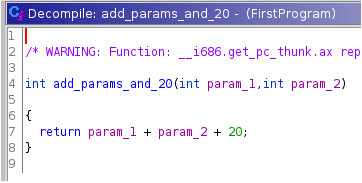
Da es keine weitere Funktion gibt, die aufgerufen wird, sind wir damit am Ende unserer Analyse angekommen. Dank des Decompilers sind wir unserem Original-Quellcode schon sehr nahe gekommen, auch wenn wir ihn nicht zu 100% wiederherstellen konnten. Aus dem Ergebnis können wir jedoch trotzdem erkennen über welche Funktionalitäten die Datei verfügt. Unser Beispiel ist dabei natürlich absichtlich einfach gewählt, um zu skizzieren, wie die Analyse eines unbekannten Programms ablaufen könnte.
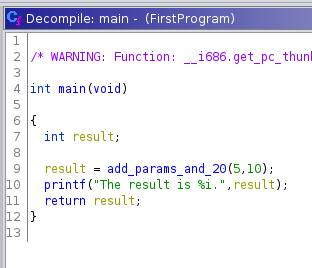
In realer Schadsoftware finden sich deutlich mehr Funktionen mit deutlich mehr Variablen. Darüber hinaus gibt es viele Techniken, die eingesetzt werden, um den Analyst*innen das Leben schwer zu machen. Man denke beispielsweise daran, dass Daten nicht im Klartext vorliegen, sondern verschlüsselt oder komprimiert sind. In diesem Fall müsste zunächst die Funktion ermittelt werden, die diese Daten entschlüsselt und bestimmt werden um welchen Algorithmus es sich handelt. Außerdem gibt es Verfahren, die das Ergebnis des Decompilers massiv verändern, sodass dieses bei weitem nicht so leicht zu verstehen ist, wie in unserem Fall.
Ausblick
Im nächsten Teil bleiben wir bei Ghidra und sehen uns ein weiteres Beispiel an. Dabei wählen wir dann einen anderen Analyse-Ansatz.




