























Was ist Phishing?

Beim Phishing lockt der Angreifer Internetnutzer auf eine Webseite, die einer bekannten Webseite, wie zum Beispiel Paypal oder Facebook, zum Verwechseln ähnlich sieht oder von dieser überhaupt nicht zu unterscheiden ist. Das Opfer denkt, dass es sich auf der richtigen Webseite befindet und gibt persönliche Information, wie zum Beispiel Passwörter oder Kreditkarteninformationen ein, um sich einzuloggen oder seine Account-Informationen zu vervollständigen. Diese persönlichen Informationen befinden sich daraufhin in den Händen der Cyber-Kriminellen, die die Phishing-Seite betreiben. Häufig werden die durch Phishing erlangten Information für weitere Angriffe oder andere kriminelle Aktivitäten genutzt.
Phishing ist aktuell der am häufigsten benutzte Angriff von Cyber-Kriminellen und der erfolgreichste. Phishing verursacht enorme finanzielle Schäden bei Privatpersonen sowie Unternehmen. Der Diebstahl von Firmengeheimnissen (z. B. Kundendaten oder noch nicht angemeldete Patente oder Ideen/Konzepte) durch Phishing kann gravierende Auswirkungen auf den wirtschaftlichen Erfolg eines Unternehmens haben. Der Diebstahl von Kundendaten kann einen enormen Imageverlust des Unternehmens nach sich ziehen. Mit den Daten lassen sich häufig komplette Identitätsdiebstähle durchführen. Dabei geben sich die Cyber-Kriminellen als die betrogene Person aus und führen weitere Aktionen in ihrem Namen aus, z. B. werden Käufe durchgeführt oder weitere Verbrechen vom gehackten PC der betrogenen Person begangen. Immer häufiger gelangen Cyber-Kriminelle an Passwörter von Cloud-Providern wie AWS oder Azure und können die Rechenleistung der Server für kriminelle Zwecke übernehmen. Identitätsdiebstähle können einen hohen bürokratischen Aufwand verursachen, der darin besteht, die von Cyberkriminellen ausgeführten Aktionen rückgängig zu machen. Noch schlimmer als der bürokratische Aufwand sind die rechtlichen Konsequenzen, die auf die betroffene Person zukommen. Für die vom PC oder Server des Opfers ausgeführten kriminellen Aktivitäten, kann die Person haftbar gemacht werden, der der PC oder Server gehört.
| https://maxmustermann:meinpasswort@www.example.com:80/ordner1/index.html?geburtsdatum=04091992#Artikel2 |
Benutzername und Passwort: Diese beiden Werte sind optional, aber erlauben es sich allein schon durch Eingabe dieser Werte in der URL bei bestimmten Webseiten einzuloggen. Der Benutzername wird mit dem reservierten Zeichen „:“ vom Passwort getrennt und das Passwort mit einem @-Zeichen vom Hostname.
Hostname: Der Hostname gibt den Servernamen an, auf dem die Webseite zum Download zur Verfügung gestellt wird. Der Hostname kann entweder als lesbare Zeichenfolge notiert werden (z. B. www.gdata.de) oder in Form einer IP-Adresse (z. B. 212.23.136.50). Jeder lesbare Domainname wird zu einer zugehörigen IP-Adresse aufgelöst, die dann für den Verbindungsaufbau verwendet wird. Aus diesem Grund kann jede Webseite auch direkt durch Eingabe der zugehörigen IP-Adresse erreicht werden.
Port: Durch den Port kann angegeben werden mit welcher Anwendung auf dem Server eine Verbindung aufgebaut werden soll. Die Anwendung, die zuständig für das Ausliefern der Webseite ist, läuft standardmäßig auf Port 80 bei HTTP bzw. Port 443 bei HTTPS. Die Angabe des Ports ist optional und wird automatisch vom Browser auf die oben genannten Standardports ergänzt. Die Portangabe wird durch einen Doppelpunkt „:“ vom Hostnamen getrennt.
Pfad und Dateiname: Da eine Webseite aus mehreren Dokumenten/Seiten besteht, sortieren die meisten Webseitenersteller diese auf dem Server zur besseren Übersicht und Strukturierung in unterschiedliche Ordner ein. Durch Angabe des Pfads und des Dateinamens, legt der Webseitenbesucher fest welche Seite er genau anfordern bzw. betrachten möchte.
Query: Durch die Query können vom Webseitenbesucher eingegebene Werte an den Server übermittelt werden. Im obigen Fall ein eingegebenes Geburtsdatum. Die Query ist mit einem Fragezeichen vom Rest der URL getrennt und besteht aus einem Bezeichner und durch ein Gleichheitszeichen „=“ abgetrennten Wert. Falls erforderlich, werden weitere Bezeichner-Wert-Paare durch das Handelskammer-Und-Zeichen „&“ ergänzt.
Fragment: Durch Angabe eines Fragments scrollt der Browser automatisch zu dem innerhalb der Webseite markierten Ankerpunkt, in unserem Beispiel zu Artikel 2. Das Fragment wird durch das reservierte Zeichen „#“ vom Rest der URL getrennt.
Phishing Strategies – The Tricks of Cyber Criminals
Bei allen Phishing-Angriffen muss das Opfer dazu gebracht werden, auf eine Phishing-URL zu klicken. Dabei bedienen sich die Cyber-Kriminellen unterschiedlicher Tricks, um das Opfer im Glauben zu lassen, dass es sich bei der URL um eine vertrauenswürdige, bekannte Seite handelt, und um den Unterschied zwischen richtiger URL und Phishing-URL zu verschleiern. Nehmen wir die untenstehenden drei URLs als Beispiel. Können Sie den Unterschied zwischen diesen URLs erkennen?
1. Mixed-script Spoofing mit ungewöhnlichen Zeichensätzen
| Original URL | http://www.google.de | U+006F, kleines o aus dem ASCII-Set |
| Phishing URL | http://www.gооgle.de | U+043E, kleines o aus dem kyrillischen Alphabet |
| Phishing URL | http://www.gοοgle.de | U+03BF, kleines Omicron aus dem griechischen Alphabet |
Vermutlich erkennen Sie einen kleinen Unterschied zwischen der zweiten und der dritten URL, wenn sie sich den Buchstaben 'o' genauer angucken. Nur würde Ihnen dieser Unterschied auch auffallen, wenn Sie nichts ahnend im Internet surfen? Vermutlich nicht. Die erste und zweite URL ist außerdem so gut wie gar nicht voneinander zu unterscheiden. Bei dieser Art des Phishings wurde von den Cyber-Kriminellen ausgenutzt, dass sich in der URL unterschiedliche Schriftfamilien darstellen lassen. Diese Schriftfamilien stellen die gleichen Buchstaben in leicht unterschiedlicher Form dar. Im obigen Beispiel wurde der Buchstabe 'o' in der lateinischen Schriftfamilie, der kyrillischen und der griechischen Schriftfamilie verwendet.
2. Unsichtbare Zeichen einfügen
Invisible Character Injection macht Gebrauch von unischtbaren Unicode-Zeichen. Wenn solche Zeichen der URL hinzugefügt werden, ist der sichtbare Text nicht von den Original URLs unterscheidbar.
3. Bidirectional Text Spoofing
Beim Bidirectional Text Spoofing werden Unicode-Schriftarten verwendet, bei denen die Schreibrichtung von rechts nach links ist. Diese Schriftarten werden mit Schriftarten kombiniert, die normal von links nach rechts ausgerichtet sind. Nachdem der Browser diese kombinierten URLs gerendert hat, sind diese bei geschickter Buchstabenwahl nicht mehr von normalen, von links nach rechts ausgerichteten URLs unterscheidbar.
4. Friendly Login URL
| http://paypal.com:login@phishingsite.org |
Eine weitere Phishingstrategie, um den Empfänger der Phishing URL zu täuschen, ist der Gebrauch von sogenannten Friendly Login URLs. Wären Sie auf diesen Phishing-Angriff reingefallen? Friendly Login URLs sind folgendermaßen aufgebaut: hostname/path und ermöglichen es, wie schon im Kapitel über URL Strukturierung geschrieben, sich allein durch den Aufruf der URL, gegenüber dem Server zu authentifizieren. Eine erneute Eingabe der Zugangsdaten auf der Webseite ist somit nicht mehr nötig. Dies geschieht, indem der Username und danach, getrennt durch einen Doppelpunkt, das dazugehörige Passwort in die URL eingefügt werden. Der Username und das Passwort stehen mit einem @-Zeichen getrennt vor dem eigentlich Hostname bzw. vor dem Webseitennamen, wie man ihn eigentlich kennt. Im obigen Beispiel ist phishingsite.org die URL, falls man keine Logindaten in der URL übermitteln würde. Durch das Festlegen von "paypal.com" als Usernamen und "login" als Passwort wird der Anschein erzeugt, dass es sich bei den Logindaten um den Domainnamen "paypal.com/login" handeln würde.
5. Namen in Subdomain
| http://paypal.login.30jka.sde{...}ajd.233.phishingsite.org |
Bei dieser Phishing-Strategie nutzen die Angreifer aus, dass die meisten Menschen von links nach rechts lesen, während die Auflösung des Hostnamen von rechts nach links erfolgt. Es wird der Name der imitierten Webseite als Subdomain in der URL eingefügt, wie man in obiger Abbildung sehen kann. Durch das Hinzufügen von beliebigen Zeichenfolgen als Subdomains, rückt die wirkliche Identität des Server (in diesem Fall phishingsite.org) aus der Browserzeile heraus und der Betrachter der Webseite liest nur den Namen der imitierten Webseite (in diesem Fall "paypal").
6. IP-Adresse und Hostname im Verzeichnis
| http://141.255.145.23/www.paypal.com |
Häufig wird bei Phishing-URLs der Hostname mit der zugehörigen IP-Adresse verschleiert. Die vorgetäuschte URL wird in den Pfad der Phishing URL platziert.
7. Vertipper und ähnliche Buchstaben
| Orginal URL: | http://www.paypal.de |
| Phishing URL: | http://www.paypaI.de |
In diesem Fall wird anstatt dem kleinen Buchstaben L (l) am Ende von www.paypal.de ein großes i (I) verwendet, und die URL somit bewusst falsch geschrieben. Es werden Buchstaben ausgetauscht, die ähnlich vom Erscheinungsbild sind.
8. Gekürzte URL
| http://goo.gl/nbKckE |
URL Shortening Services verkürzen nicht nur die Länge der ursprünglichen URL, sie erzeugen eine neue URL, die aus dem Service Seitennamen (z.B. bit.ly oder goo.gl) und einer zufälligen Abfolge von Buchstaben und Ziffern besteht. Aus der verkürzten URL lässt sich nicht erkennen auf welche Seite der Besucher weiter geleitet wird. So wird die Identität der Webseite des Angreifers durch die Weiterleitung bedingt verschleiert.
9. Kodierte URL Verschleierung
| Dword | http://3515261219 |
| Octal | http://0321.0206.0241.0043 |
| Hexadecimal | http://0xD186A123 |
Normalerweise werden IP-Adresse als Blöcke mit vier (IPv4) bzw. sechs (IPv6) Ziffern/Zeichen dargestellt. Sie ist aber auch in Hexadezimal-, Oktal- oder in Binärschreibweise darstellbar. Betreiber von Phishing-Webseiten verwenden diese Schreibweise, um den ausgeschriebenen Namen der Webseite (Hostname) zu verschleiern.
10. Domain Shadowing
Neben der Strategie einen fremden Webserver zu hacken, diesen zu kompromittieren, und anschließend den richtigen Hostname zu verschleiern, wird beim Domain Shadowing der gute Ruf der Second-Level-Domain ausgenutzt. Die Cyberkriminellen verschaffen sich Zugriff auf den DNS Management Account des Webseitenbetreibers und fügen Subdomains zu der Webseite hinzu. Diese Subdomains werden auf IP-Adressen des Angreifers weitergeleitet, in dem der Angreifer die neu erstellten Subdomains mit mit seinen eigenen IP Adressen im DNS Management Account verknüpft. Bei diesem Ansatz wird nicht der Webserver der Ziel-Organisation gehackt, sondern der DNS Account. Das hat für Angreifer den entscheidenden Vorteil, dass es deutlich länger dauert die Phishing-Webseite zu entdecken und zu entfernen, weil es auf dem Original Webserver keine Hinweise auf einen Angriff gibt. Hier ist eine sorgfältige Zusammenarbeit mit dem Registrar und/oder DNS Administrator ist nötig, um sicherzustellen dass die Original-Webseite des Webseitenbetreibers nicht von Phishing betroffen ist.
11. Vertrauenerweckende Schlüsselwörter
| http://secure-login-paypal.de |
Um das Vertrauen des Opfers zu erlangen, werden seriös klingende und vertrauenerweckende Schlüsselwörter in der URL verwendet und mit dem Namen der angegriffenen Organisation verknüpft. Im obigen Beispiel lässt sich erst durch die Überprüfung der WHOIS-Daten herausfinden, ob diese Domain von Paypal registriert wurde oder nicht.
Machine Learning
Wer die URL beim Surfen genau überprüft bevor er sie angeklickt, könnte die Täuschungsmanöver teilweise erkennen. Da es aber menschlich ist, dass wir beim alltäglichen Surfen häufig in Eile oder unkonzentriert sind, sind Fehler schnell passiert. Daher ist es besser und zuverlässiger, wenn die unterschiedlichen Phishing-Typen maschinell erkannt werden.
Alle vorgestellten Phishing-Strategien verfolgen ein Ziel, nämlich die richtige Identität der Webseite zu verschleiern und dabei dem Empfänger der URL weiszumachen, dass es sich bei der gefälschten Webseite um das Original handelt. Nimmt man all diese bekannten Phishing-Strategien als Grundlage, lassen sich aus einer URL bestimmte lexikalische Eigenschaften extrahieren. Diese werden anschließend als Entscheidungsgrundlage genutzt, um zu entscheiden, ob es sich bei dieser zu untersuchenden URL um eine harmlose oder eine Phishing-URL handelt. Im Folgenden sind ein paar Beispiele für solche lexikalischen Eigenschaften aufgezählt. Diese Merkmale lassen sich in die Gruppen Count-Features, Pattern-Features, N-gram Features, Length- Features und Binary Features unterteilen. Im Folgenden sind Beispiele für die unterschiedlichen Feature-Gruppen aufgezählt:
Count Features:
In dieser Gruppe werden bestimmte Eigenschaften gezählt. Z.B.:
- Anzahl der Punkte im Hostname
- Häufigkeit der Zeichenfolge 'www' im Hostname
- Anzahl von @-Zeichen im Hostname
Pattern Features
Hier werden bestimmte Muster erfasst. Z.B.:
- N-gram Features
- Ähnlichkeitswerte zu den am meisten besuchten Webseiten weltweit
- Wechsel von Klein- zu Großschreibung
Length Features
In dieser Gruppe geht es um die Länge von bestimmten Eigenschaften. Z.B.:
- Länge des ersten Pfadabschnitts
- Länge der Top-Level-Domain
- Länge der Query
Binary Features
Binäre Merkmale lassen sich auf Paare wie wahr/falsch, ja/nein, vorhanden/nicht vorhanden etc. abbilden.
- IP-Adresse anstatt Hostname
Die unterschiedlichen lexikalischen Eigenschaften werden, so weit sinnvoll, jeweils für den Hostname, den Pfad, die Query und die gesamte URL berechnet. Viele Punkte in der URL sind bis zu einem gewissen Grad nichts ungewöhnliches. Punkte im Pfad deuten aber auf versteckte Ordner auf dem Server hin, was ein Indiz auf einen gehackten Server ist. Eine separate Berechnung der Feature-Werte für die unterschiedlichen URL-Segmente ist durchaus sinnvoll.
Bei den N-grams haben wir zwischen One-grams, Two-grams, Three-grams und Four-grams unterschieden. Dabei wird die URL, der Hostname, der Pfad und die Query jeweils in Abfolgen von einem, zwei, drei oder vier Zeichen unterteilt. Der Hostname paypal.com wird zum Beispiel in die Three-grams pay, ayp, ypa, pal, al.c, l.c, .co und com unterteilt. Anschließend wird berechnet wie wahrscheinlich es ist, dass diese N-grams zu Phishing oder harmlosen Webseiten gehören.
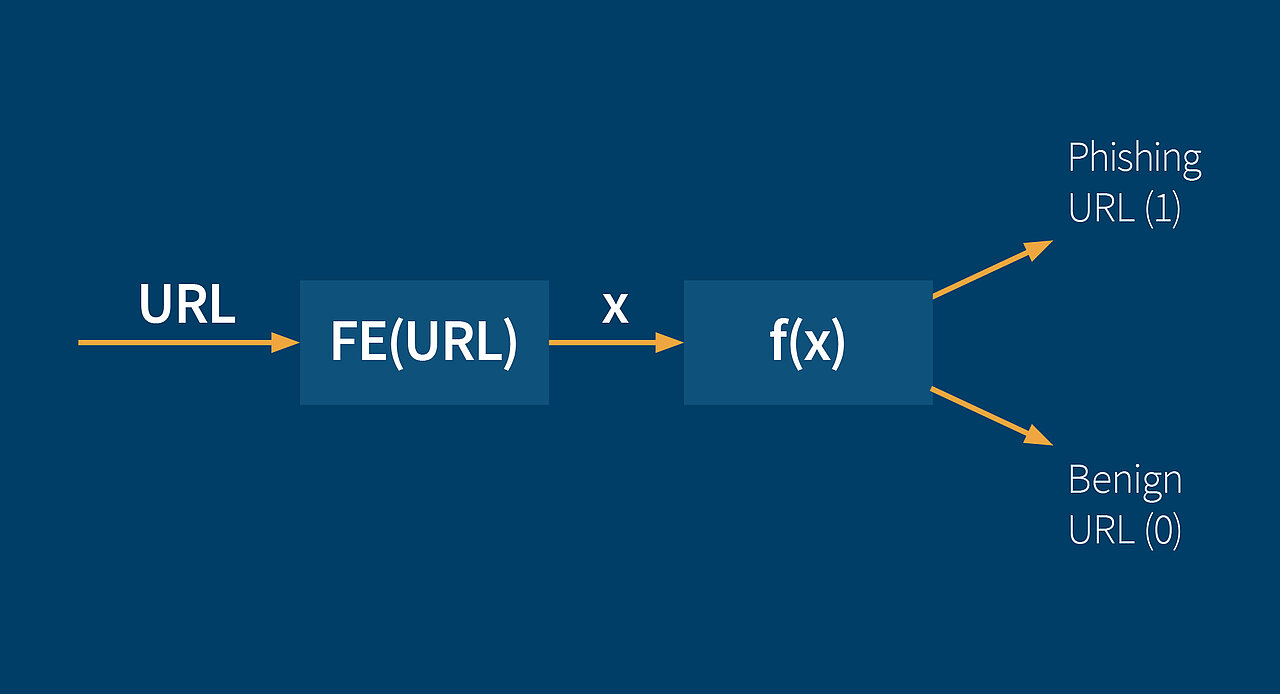
FE = Feature Extraction
Diese lexikalischen Eigenschaften sowie weitere werden als Eingabe für eine Funktion genommen, die entscheidet, ob es sich bei einer vorliegenden URL um eine Phishing oder um eine harmlose URL handelt. Dabei werden manche Eigenschaften mehr als andere gewichtet, weil sie mehr Indizien dafür liefern, dass eine URL eine Phishing-URL sein könnte. Auch berücksichtigt diese Funktion bestimmte Kombinationen von lexikalischen Eigenschaftswerten, die falls sie auftreten, eine hohe Wahrscheinlichkeit auf das Vorhandensein einer Phishing-Webseite liefern.
Die lexikalischen Eigenschaftswerte von bekannten Phishing-URLs und bekannten harmlosen URLs wurden nun vier unterschiedlichen Machine Learning Algorithmen (einem Neuronalen Netz, einem Rainforest Algorithmus, einem Decision Tree Algorithmus und einem Support Vektor Machine Algorithmus), sowie einem aus allen vier Machine Learning Algorithmen kombiniertem Klassifizierer als Eingabe gegeben. Die genannten Machine Learning Algorithmen, sowie der kombinierte Klassifizierer lernen beim Machine Learning Prozess die optimale Gewichtung und die besten Kombinationen von lexikalischen Eigenschaftswerten. Optimal bedeutet in diesem Fall, dass unter Berücksichtigung von diesen gelernten optimalen Kombinationen und der gelernten optimalen Gewichtung, die Anzahl an richtig klassifizierten URLs maximiert wird. Ob eine URL im Lernprozess richtig klassifiziert wurde, ist leicht festzustellen da im Lernprozess nur bekannte Phishing und bekannte harmlose URLs verwendet werden. Klassifiziert ein Machine Learning Algorithmus im Lernprozess eine URL falsch, wird eine Anpassung an der Gewichtung der lexikalischen Eigenschaften in der Funktion vorgenommen. Der automatisierte Lernprozess kann also vereinfacht betrachtet als Anpassung der Gewichtung der lexikalischen Eigenschaften und dem Finden von guten Kombinationen von Eigenschaften gesehen werden. Nach Beendigung des Lernprozesses, erhält man eine Funktion, die unbekannte URLs anhand der extrahierten Gewichtungen aus dem Trainingskorpus mit einer hohen Genauigkeit richtig klassifizieren kann. Am Beispiel des Decision Tree Algorithmus, sind die gelernten Regelsätze auch visualisierbar:
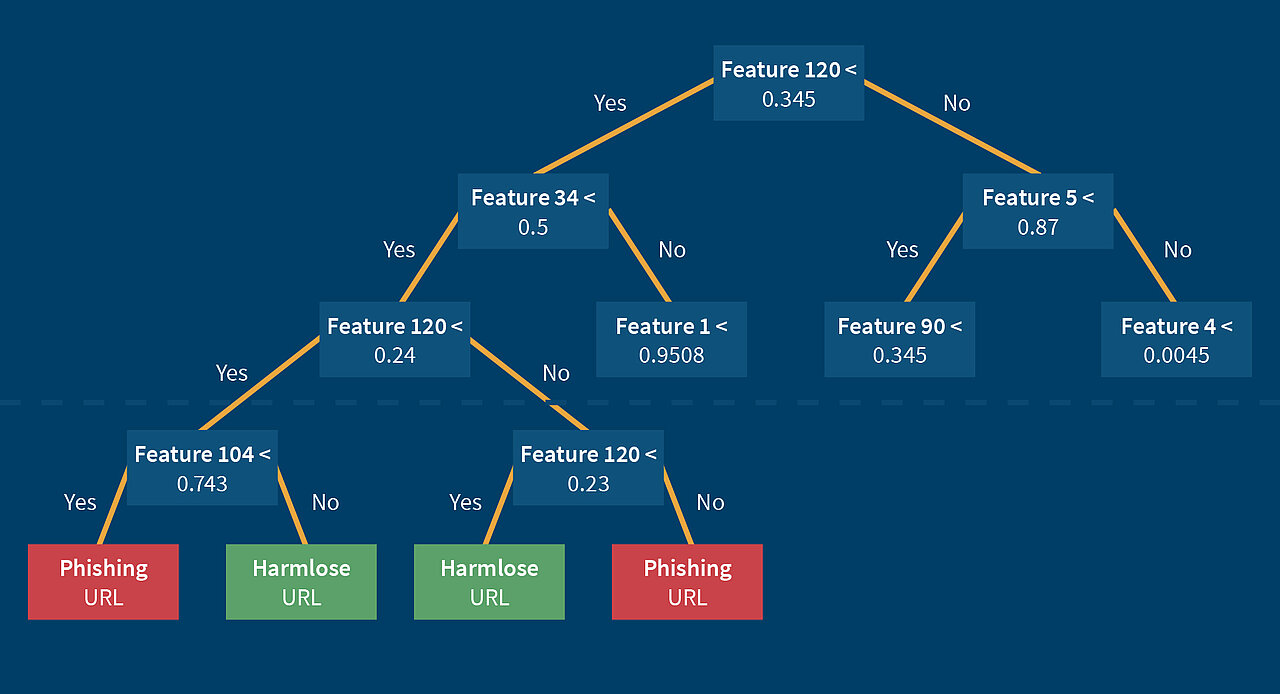
Es lässt sich ein Entscheidungsbaum (engl. Decision Tree) erstellen, der eine gefundene Anzahl von Regelsätzen enthält, an denen entschieden wird ob eine Webseite eine Phishing-Webseite oder eine legitime Webseite ist. Der Baum besteht aus einer Menge von Knoten, an denen jeweils eine Frage überprüft wird. Falls diese für eine bestimmt URL mit „Ja“ beantwortet wird, wird nach links verzweigt, falls sie mit „Nein“ beantwortet wird, nach rechts. Die Frage ist immer nach dem Schema Feature x < Wert ? aufgebaut. Am Ende gelangt man immer zu einem Knoten, in dem die Klassifizierung für die zu überprüfende URL steht. Im Lernprozess werden die Features, die das Lernset am besten in die zwei Klassen (Phishing URL und harmlose URLs) unterteilen im oberen Teil des Baumes angeordnet, und die Features, die schlechter unterteilen bzw. auf eine komplexe Vorsortierung aufbauen, weiter unten im Baum angeordnet. Wie in obiger Abbildung zu erkennen, werden bestimmte Features (wie z.B. Feature 120) auch mehrmals abgefragt. Die Werte anhand derer an jedem Knoten unterschieden wird, wie verzweigt wird, werden beim Machine Learning Prozess ermittelt. Das Machine Learning beim Decision Tree Algorithmus optimiert also die Reihenfolge und die Regelsätze, um möglichst viele URLs aus dem Trainingsset richtig zu klassifizieren.
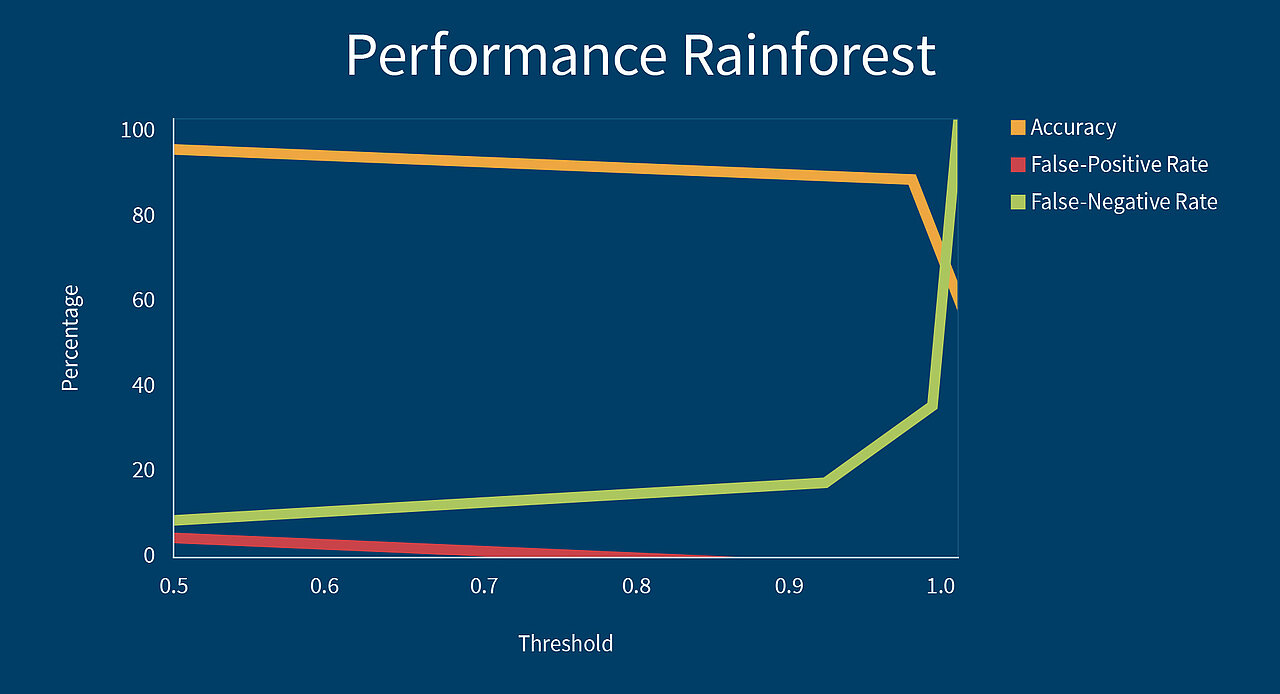
Als Vorbereitung vor dem eigentlichen Klassifizieren, werden von den Machine Learning Algorithmen für jede gegebene URL eine Wahrscheinlichkeit berechnet, mit der diese URL eine Phishing URL ist. Beim normalen Klassifizieren könnte man anschließend so vorgehen, dass man alle URLs die eine Wahrscheinlichkeit größer gleich 50% besitzen als Phishing URLs klassifiziert. Man kann den Schwellwert aber auch erhöhen und beispielsweise auf 90% setzen, das heißt man klassifiziert nur noch URLs, die eine Wahrscheinlichkeit größer gleich 90% besitzen, als Phishing-URL und alle, die eine Wahrscheinlichkeit darunter besitzen, als harmlos. Dadurch geht man sicher, dass der Klassifizierer weniger Fehler macht und weniger URLs als Phishing klassifiziert werden, die eigentlich harmlos sind (sogenannte False Positives). Durch das Erhöhen des Schwellwerts erhöhen sich allerdings auch die URLs, die Phishing URLs sind, aber nicht erkannt werden (sogenannte False Negatives). Das Setzen des Schwellwerts ist somit ein Abwägen zwischen Fehlalarmen (False Positives) und verpassten Erkennungen (False Negatives). Wir haben die vier verschiedenen Machine Learning Algorithmen bezüglich der Skalierbarkeit der False-Positive-Rate zum Schwellwert untersucht und beim Rainforest Algorithmus die, in untenstehender Abbildung illustrierten, guten Ergebnisse erhalten. Wie erwartet, sinkt die False-Positve Rate auf Kosten der False Negative Rate.
Unsere erzielten Genauigkeiten, sowie False Positive Rates und False Negatives Rates, sind in dieser Reihenfolge in untenstehender Tabelle aufgelistet. Dabei werden die erzielten Ergebnisse für die vier Machine Learning Algorithmen Multi Layer Perceptron, Reinforest, Decision Tree, Support Vector Machine und den kombinierten Klassifizierer unter den Schwellwerten 0.5 bis 1.0 ausgewertet.
Die höchste Genauigkeit erhielten wir unter Anwendung des Neuronalen Netzes mit einer Genauigkeit von 98.08% auf 525.215 klassifzierten URLs. Die Machine Learning Algorithmen erneuern das Lernset regelmäßig mit neuen URLs und erneuern ihre Klassifizierungsfunktion durch erneutes Machine Learning mit aktuellen Daten. Somit werden auch neue Angriffsmuster von Cyberkriminellen erkannt und können verhindert werden.

Advantages of Machine Learning – a smart approach
Die gängigsten Anti-Phishing Maßnahmen basieren auf dem Einsatz von Blacklists, in denen Sammlungen von verbotenen Phishing URLs aufgelistet sind. Wird eine Webseite aufgerufen, die sich auf einer Blacklist befindet, wird der Zugang zu dieser Seite sofort gesperrt. Ein entscheidender Nachteil von Blacklists ist allerdings, dass erst Personen auf einen Phishing Link reinfallen müssen und somit Schaden nehmen, bevor die URL der Blacklist hinzugefügt wird. Ein Machine Learning Algorithmus kann allerdings auch unbekannte URLs richtig klassifizieren und ist somit ein proaktiver Ansatz. Ein weiterer Nachteil von Blacklists ist, dass es sehr aufwendig und praktisch unmöglich ist die Blacklists stets aktuell zu halten. Das liegt auch daran, dass Cyber-Kriminelle die URLs kontinuierlich verändern und anpassen. Des weiteren dauern 63% der Phishing Angriffe nicht länger als zwei Stunden [4]. Machine Learning Algorithmen sind in der Lage URLs direkt und automatisiert zu erkennen. Die Klassifizierungsfunktion wird durch kontinuierliches Trainieren stets auf dem neusten Stand gehalten und schützt somit auch gegen neue Angriffsstrategien.
Referenzen
[1] Lee Neely. Threat Landscape Survey 2017, aug 2017.
[2] Steve Morgan. 2017 Cybercrime Report. Technical report, Cybersecurity Ventures, 2017. URL.
[3] Xi Chen et al., Analyzing the Risk and Financial Impact of Phishing Attacks using Knowledge based Appraoach. 2009. URL.
[4] Lingxi Liu Huajun Huang, Junshan Tan. Countermeasure Techniques for Deceptive Phishing Attack . 2009. URL.